You don't want to waste time and money with a complex tool?
• Are you a Software / System Engineer? Trace the association between specifications and requirements, verify that the test plan covers all the requirements of your specifications, cover your specification requirements in your source code. Increase the consistency and ease of reading of requirements, implement the V-model required by IEC 62304, DO178C, ISO 26262 etc.
• Are you a Buyer? Make sure that sub-contractor response meets all requirements or all headings of your RFP or RFI. Check the coverage rate between different offers.
• Are you a BID Manager? Reassure your customer: prove that your proposal covers all the parts and requirements of the call for tender. Make sure your document is clear and easy to read.
• Are you a Training Manager? Ensure that your training materials cover all upstream technical documentation. Automatically identify the boards to be modified during an update.
• Are you a Quality Manager? Make sure that your quality system meets the requirements of your quality standard EN9100, ISO9001, ISO/TS16949 etc. Present the standard matrix vs process to your reviewer.
• Are you a Buyer? Make sure that sub-contractor response meets all requirements or all headings of your RFP or RFI. Check the coverage rate between different offers.
• Are you a BID Manager? Reassure your customer: prove that your proposal covers all the parts and requirements of the call for tender. Make sure your document is clear and easy to read.
• Are you a Training Manager? Ensure that your training materials cover all upstream technical documentation. Automatically identify the boards to be modified during an update.
• Are you a Quality Manager? Make sure that your quality system meets the requirements of your quality standard EN9100, ISO9001, ISO/TS16949 etc. Present the standard matrix vs process to your reviewer.
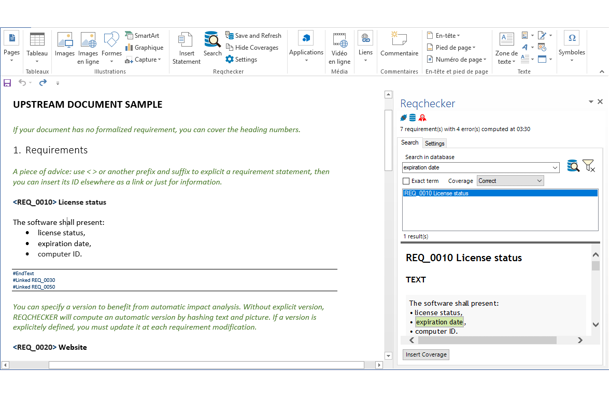
Keep your existing documents ! Reqchecker™ analyses WORD, EXCEL, PDF, source code and some formats. Author your documents with the powerful Reqchecker add-in for MS WORD. Manage your customized attributes.
No requirements in your upstream documents? No problem, Reqchecker™ can use the heading numbers for PDF and WORD documents.
No requirements in your upstream documents? No problem, Reqchecker™ can use the heading numbers for PDF and WORD documents.
Automatic controls increases consistency and ease of reading.
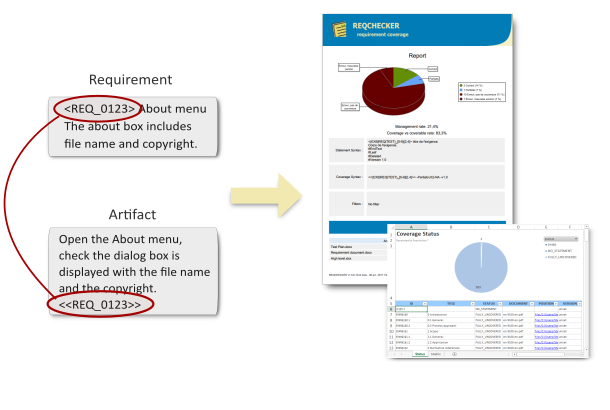
Requirement traceability includes statuses, quantifiable partial coverage, management rate, coverage rate and more.
Change the input documents and Reqchecker™ shows where your documents must be updated. The automatic impact analysis checks propagation of all requirement changes using version management.
Requirement traceability includes statuses, quantifiable partial coverage, management rate, coverage rate and more.
Change the input documents and Reqchecker™ shows where your documents must be updated. The automatic impact analysis checks propagation of all requirement changes using version management.
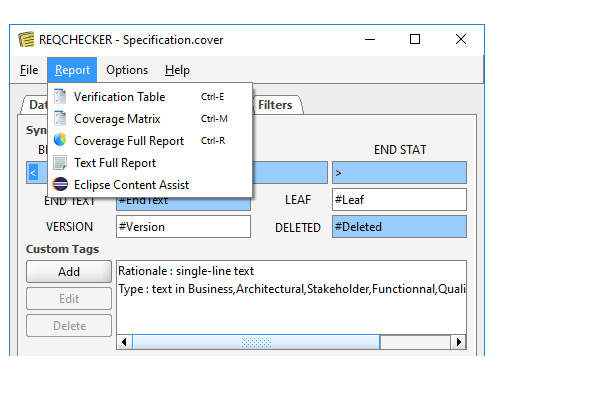
REQCHECKER™ generates several reports to meet different needs:
- PDF full report is designed to be easily disseminated to other stakeholders of your project
- EXCEL interactive reports are designed to effectively identify and solve problems
- Markdown structured text report can be displayed in a WEB browser









